We’ve been doing some fantastic, sometimes cutting edge, engineering work at Mattermark. However, whenever I give talks about what we’re doing at Mattermark, I always seem to have the same conversation afterwards:
“Wow, I’d heard about Mattermark, but I didn’t realize that you guys were doing such great work!”
At first, I took this as a compliment. But soon, I started to realize that this was actually an issue. We were clearly not doing a good enough job communicating to the community about our work. This blog is our medium to set the record straight.
Mattermark’s Vision
You may be familiar with our high level vision of “organizing the world’s business information.” But that might sound vague and overstated if we don’t explain how serious we are about it.
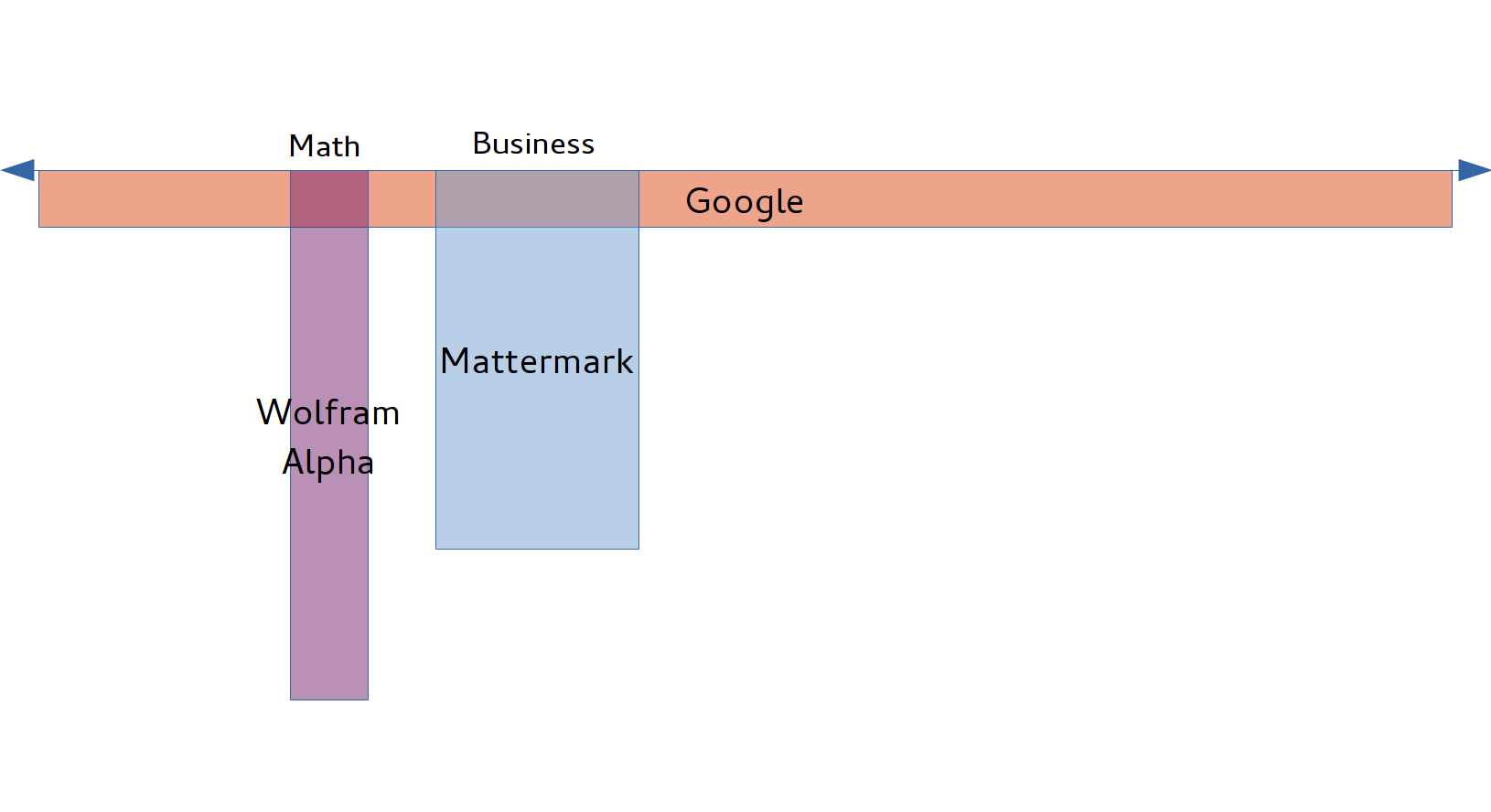
An apt analogy for Mattermark that I like to use is: A mix of Google and Wolfram Alpha for business information. Why? Google is an incredibly broad knowledge engine that can answer questions ranging from “Who is Will Smith’s son?” to “What is the capital of Kazakhstan?”. However, the questions it can answer are actually pretty shallow. It can’t give you results for complex queries like, “What is the integral of f(x) = sin(x) + x²?” or, “What are the fastest growing companies with fewer than 25 employees in the Bay Area?” On the other end of the spectrum, Wolfram Alpha can answer very deep and complex questions, but only about a pretty narrow topic: Math and Statistics.
Mattermark aims to be somewhere in between. We’re going to cover a much broader topic than Wolfram Alpha (business), but nowhere near as broad as Google (good luck to anyone who tries!). We’re also going to go far deeper than Google, but not as deep as Wolfram Alpha. We want to be realistic.
Path to realization
We’re well on our way to realizing our vision, but there’s still a long way to go. Organizing the world’s business information is only part of it; we also intend to make that information intuitively searchable. At a high level, we can split up our activities into three categories:
1. Data Mining
We are crawling already-structured sources of data, such as Twitter and Facebook, scraping information across the web, and performing Information Retrieval-related Machine Learning jobs to extract structured data from unstructured sources, such as news articles. These jobs number in the hundreds, and will expand into the thousands. Managing all of these jobs and providing scalability and reliability is something we’re tackling with state-of-the-art technology such as Mesos and Chronos.
2. Proprietary Data Analysis
On top of all the data we collect, we perform our own Data Analysis using statistics and Machine Learning. This provides our customers with growth rankings of companies, categorization by industries such as “Real Estate” and “Health IT” and much more.
3. Data Search
Collecting this vast array of data is all good and fine, but if our customers can’t access and search this data in a meaningful and intuitive way, it’s tantamount to useless. We’ve already enabled sophisticated search features across our database of companies with Elastic Search, but there’s so much more to do.
Over the next few months (and hopefully years), we’ll delve into more detail about what we’ve been working on. We’ll also share what we’ve learned solving the hard problems that we face, in the realms of Distributed Computing, Machine Learning, reactive frontends and a lot more.
If this is already pretty interesting to you, and you’re itching to hear more, I’d be more than happy to get a coffee with you if you’re in San Francisco, or get on the phone with you if you’re not. Shoot me an email at samiur@10.147.21.165 to set something up. In case you’re wondering, we are hiring for Full Stack Engineers, Machine Learning Engineers and DevOps Engineers of all levels to make this vision a reality: https://mattermark.com/jobs. Regardless, stay tuned for more of what lays ahead =).
Discuss this post on Hacker News.